微软一直在悄悄构建自己的图像生成器。该公司AI超级智能团队周四宣布的MAI-Image-2已经登上了Arena.ai排行榜第三名——仅次于谷歌和OpenAI的模型,使微软在这个它之前外包给合作伙伴的领域成为了真正的竞争者。

MAI-Image-2现已可在MAI Playground中使用,正在逐步推广到Copilot和Bing Image Creator。API访问目前仅限于选定的企业客户,更广泛的可用性将在Microsoft Foundry上很快推出。
测试MAI-Image-2
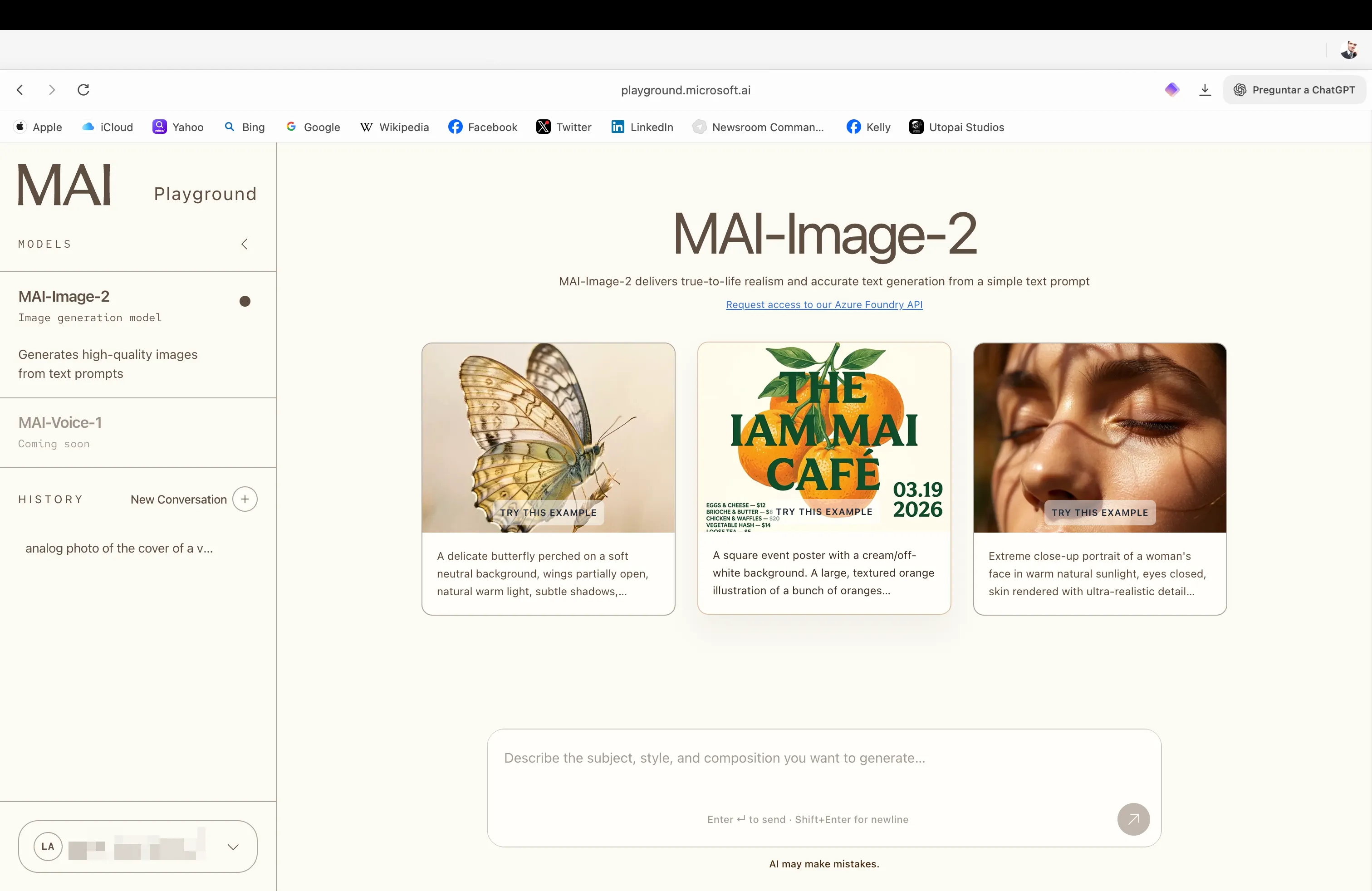
当你打开MAI Playground时,首先注意到的是它的低调。界面简约干净,视觉上介于Claude和Hume之间,没有Midjourney那种极简主义仪表板的能量,也没有Gemini那种聊天机器人体验。
图像本身确实相当强大。照片真实感是这里的真正优势——模型对自然光、表面纹理和空间关系有很好的把握。它还没有达到谷歌Nano Banana Pro的水平(该模型仍然统治排行榜是有原因的),但在一些真实感测试中,它出人意料地接近。

更好的提示可能会推动它更进一步;当我们调整描述时,我们的初步结果明显改善。
即使是不符合逻辑参数的复杂、不现实的场景,模型也能正确处理,在身体比例、肢体位置、深度和空间定位等细节上击败了其他模型。
例如,这张狗在海洋中央骑自行车的图像可以说是我们在零样本测试中生成的最准确的图像。

文本生成是一个真正的亮点。MAI-Image-2处理复杂排版的一致性远超我们的预期——图像中的大块文本、海报、标牌——没有大多数模型常见的乱码。
我们甚至将其推向多语言文本:它设法生成了一些汉字,尽管准确性并不完美。尽管如此,它尝试并取得部分成功的事实是值得注意的。

模型很好地理解艺术风格,可以在照片写实主义、平面设计美学和插图风格之间切换,没有太多摩擦。它仔细阅读提示,包括风格说明,并在另一端提供连贯的内容。对于广泛的视觉任务,它很灵活。
现在谈谈更严峻的事实。
MAI-Image-2被积极过滤——比谷歌Imagen更严格,也比OpenAI的DALL-E更严格。我们运行了通常的蜘蛛追逐女人的卡通画测试,结果被断然拒绝。同样,那是一幅画——关于蜘蛛的。这里的内容审核调整到了一个会让任何在灰色区域、恐怖插图或任何读起来有点紧张的内容中进行创意工作的人感到沮丧的水平。
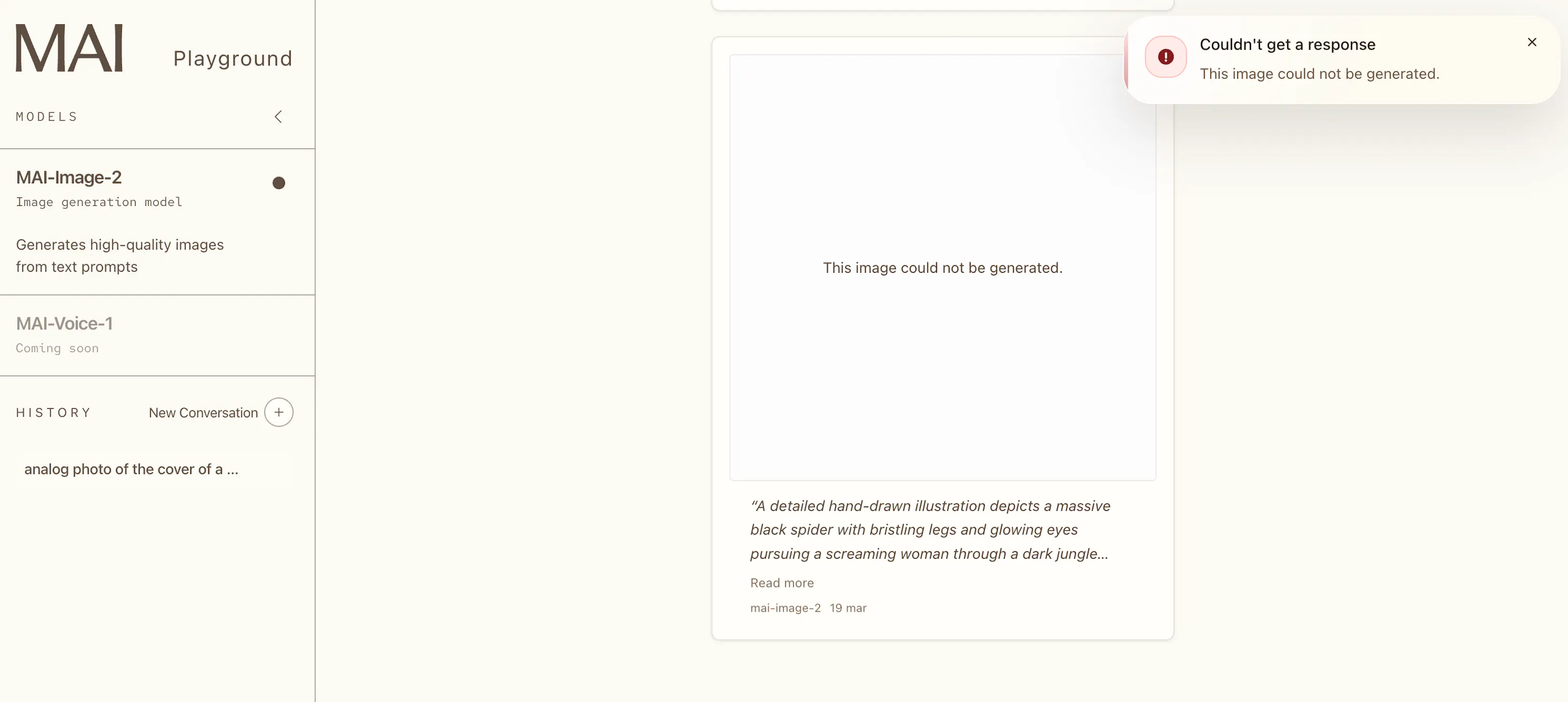
使用限制同样严格。每次生成都会触发30秒的冷却时间。生成15张图像后,你将被锁定24小时。对于随意的实验,这是可以管理的。对于任何类型的工作流程,这在原生UI中是一个交易破坏者。
也只有一种分辨率:1:1。没有横向,没有纵向,没有自定义比例。在2026年,这是一个重大限制——特别是对于社交媒体内容,而这正是微软可能希望将其嵌入Copilot的地方。
说到Copilot:MAI-Image-2还没有在那里。推广正在进行中,但截至今天,你真正想要它的产品还没有它。
还有一个缺失的部分:这纯粹是一个文本到图像的工具。没有图像到图像,没有修复,没有扩展,没有参考图像支持。对于期望接近Firefly或Midjourney编辑功能的用户来说,这会感觉半成品。
我们的看法
MAI-Image-2的表现比其排行榜排名所暗示的要好。在我们的动手测试中,它在图像质量和文本渲染方面击败了GPT-Image,考虑到GPT-Image在Arena.ai排行榜上位于它之上,这很有趣。基准位置并不总是讲述完整的故事。
构建这个的战略逻辑是清晰的。微软一直在为Copilot授权OpenAI的图像模型,同时资助OpenAI最大的竞争对手Anthropic。拥有一个强大的内部模型减少了依赖性,在大规模上削减了成本,并让微软可以在不请求许可的情况下迭代一些东西。
从这个角度来看,MAI-Image-2不需要击败Nano Banana。它只需要足够好——而它确实如此。
问题是产品约束。生成上限、严格的内容政策、仅1:1输出、缺失的编辑功能等;这些是限制现实世界实用性的限制。一个如此强大的模型应该配备与之匹配的基础设施。
MAI-Image-2是一个强大的技术基础,被保守的产品决策所束缚。一旦微软放宽限制,这就成为一个严肃的竞争者。目前,它是微软图像堆栈可能真正成为什么的一个有希望的预览。
本网站所有区块链相关数据与资料仅供用户学习及研究之用,不构成任何投资建议。转载请注明出处:https://www.lianxinshe666.com/2026/03/20/%e5%be%ae%e8%bd%af%e5%8f%91%e5%b8%83mai-image-2%e6%96%87%e6%9c%ac%e5%88%b0%e5%9b%be%e5%83%8f%e6%a8%a1%e5%9e%8b-%e8%a1%a8%e7%8e%b0%e8%b6%85%e9%a2%84%e6%9c%9f/





