微软刚刚发布了一项突破性技术,让OpenAI的GPT和Anthropic的Claude两大AI模型协同工作,创造了一个超越所有现有AI研究工具的新系统。

双模型协作:Critique与Council模式
微软在周一为Copilot的Researcher工具宣布了两项新功能——Critique和Council。这两种模式让GPT和Claude在同一研究任务中协同工作,根据微软在行业基准测试中的表现,其得分超过了所有参与测试的系统,包括顶级AI公司的模型。
“Critique是一个专为复杂研究任务设计的新型多模型深度研究系统。它将生成与评估分离,并利用来自前沿实验室(包括Anthropic和OpenAI)的模型组合,”微软解释道。”一个模型主导生成阶段,规划任务,迭代检索并生成初稿,而第二个模型专注于审查和精炼,在最终报告生成前充当专家评审员。”
解决AI研究的关键问题
Critique旨在解决当前AI研究工具的一个基本问题:所有现有工具的工作方式都相同。用户提出问题,一个模型规划搜索、搜集来源、撰写报告并返回给用户。这个单一模型在没有检查的情况下完成所有工作。
这可能导致一些幻觉(hallucinations)混入、引用错误、虚假或不准确的主张等。
Critique将这个工作流程分为两部分。GPT处理第一阶段——规划研究、提取来源并撰写初稿。然后Claude作为严格的编辑介入,审查报告的事实准确性、引用质量以及答案是否真正解决了所问问题。只有经过这次审查后,最终报告才会到达用户手中。
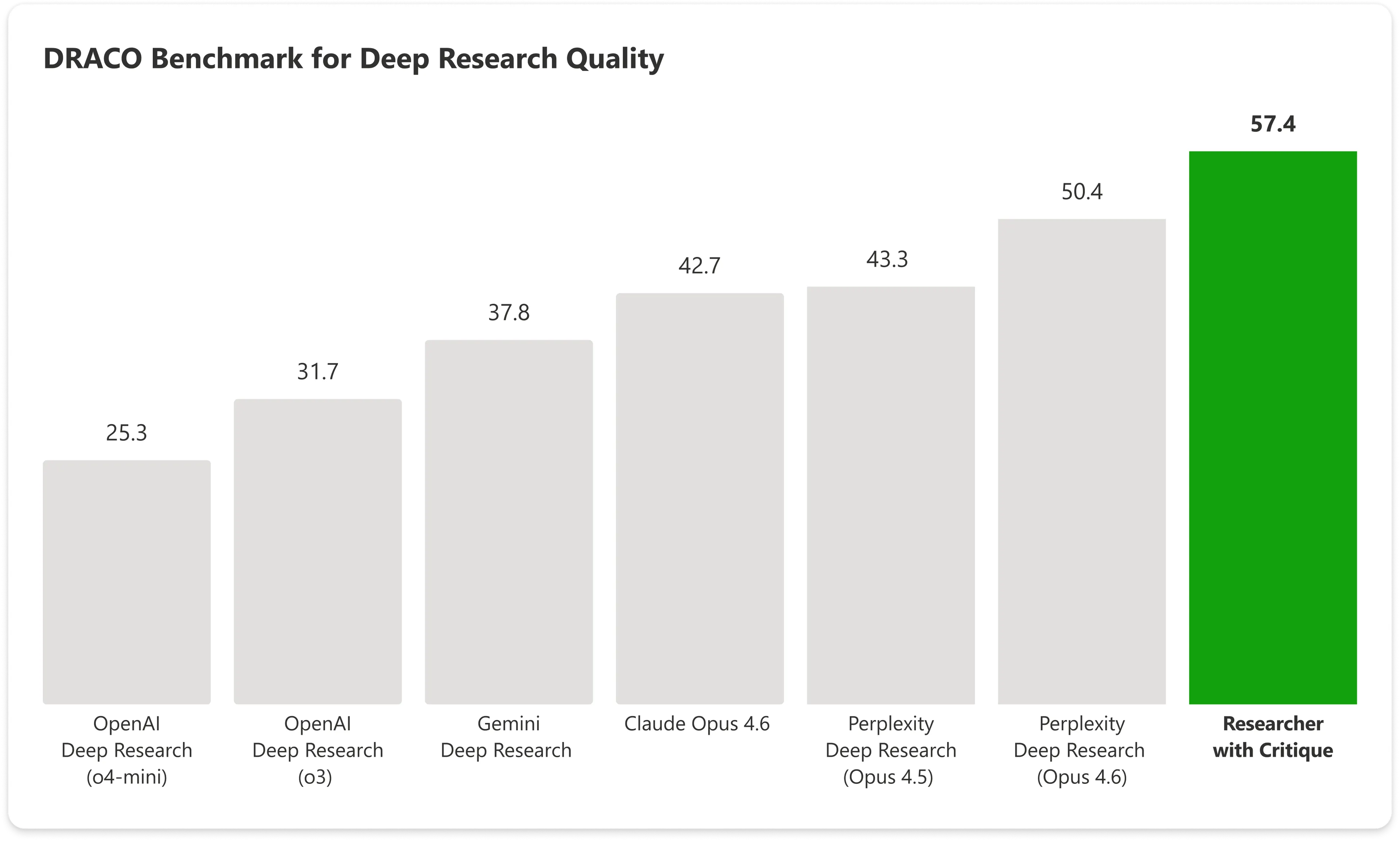
在DRACO基准测试中——一个涵盖医学、法律和技术等10个领域100个复杂研究任务的标准测试——配备Critique的Copilot得分为57.4分,而Anthropic的Claude Opus 4.6单独得分为42.7分。微软的组合系统比次优结果高出近14%。
Council模式:并行竞争
第二个功能Council采用不同的方法解决相同问题。Council不是让一个模型审查另一个的工作,而是同时运行GPT和Claude,并将它们的完整报告并排放置。然后第三个”法官”模型读取两者,并撰写摘要解释两个AI在哪里达成一致,在哪里存在分歧,以及每个AI捕捉到了另一个遗漏的独特角度。
在Critique中,模型本质上是相互协作,而在Council中,模型相互竞争。
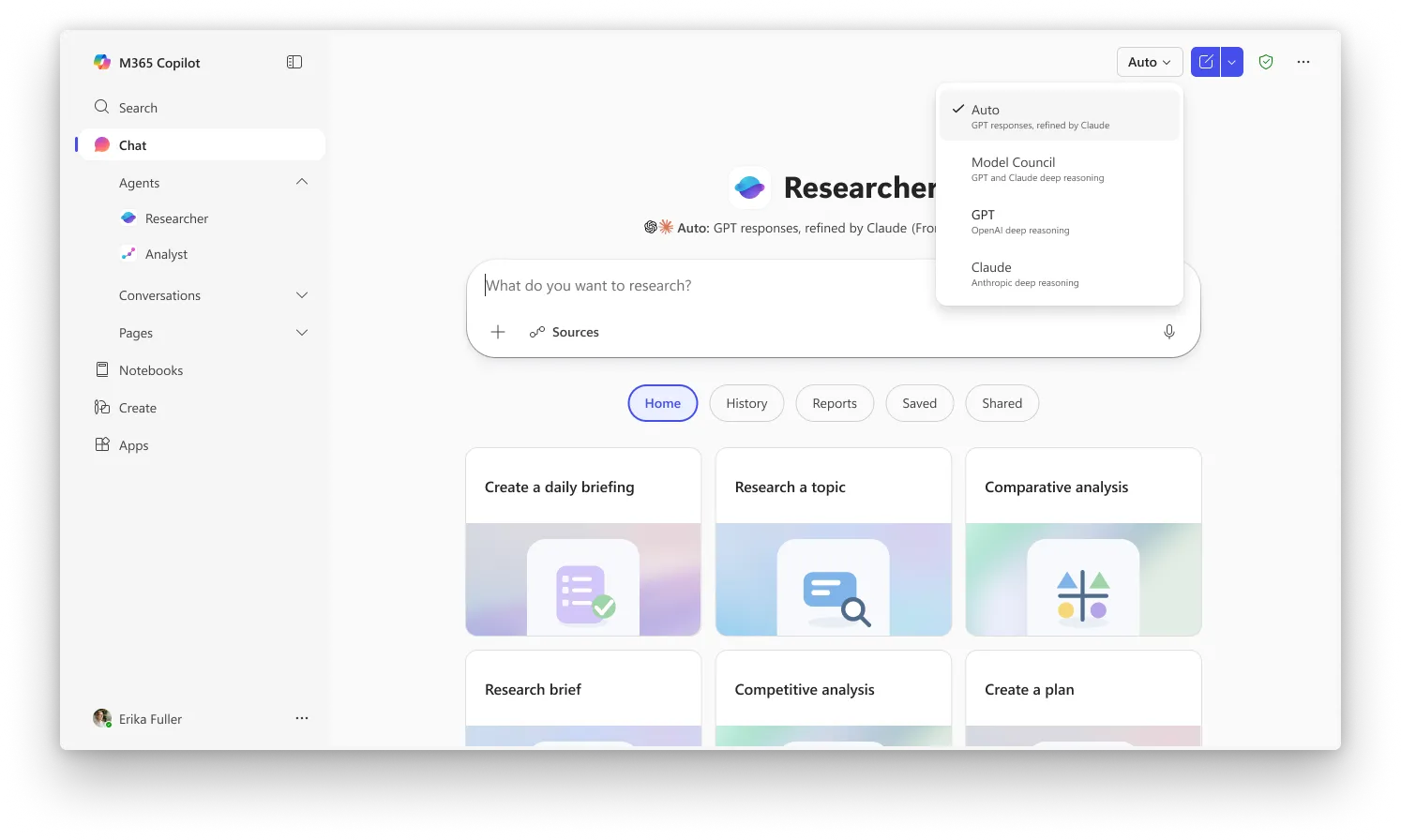
Critique是Researcher中的默认体验,而Council需要用户从选择器中选择”Model Council”来激活并排模式。这两个功能目前可供参加微软Frontier计划的用户使用,这是Copilot最新功能的早期访问渠道。
AI研究工具的新竞赛
深度研究AI一直是今年科技领域最热门的竞赛之一。谷歌在2024年12月宣布了其Gemini研究代理,OpenAI在2025年2月发布了自己的研究代理,xAI紧随其后,Perplexity加倍投入,而Anthropic的Claude在需要详细、引用答案的专业人士中建立了忠实追随者,于去年4月推出了其代理。
OpenAI和微软有着数十亿美元的合作伙伴关系,但微软的赌注是:没有单一模型能长期保持领先地位,真正的价值在于编排层,该层将任务路由到最佳组合。
本网站所有区块链相关数据与资料仅供用户学习及研究之用,不构成任何投资建议。转载请注明出处:https://www.lianxinshe666.com/2026/03/31/%e5%be%ae%e8%bd%af%e8%ae%a9gpt%e4%b8%8eclaude%e5%8d%8f%e5%90%8c%e5%b7%a5%e4%bd%9c%ef%bc%9a%e6%96%b0ai%e7%a0%94%e7%a9%b6%e5%b7%a5%e5%85%b7%e8%b6%85%e8%b6%8a%e6%89%80%e6%9c%89%e7%ab%9e%e4%ba%89%e5%af%b9/





