AI工程师凯尔·赫斯林将Jackrong的两个Claude Opus 4.6和GLM-5.1精调模型融合成一个”弗兰肯斯坦式合并”模型,结果这个180亿参数的混合模型在廉价GPU上运行,性能却超越了阿里巴巴最新的350亿参数模型。

赫斯林是AI基础设施工程师,他将Jackrong的两个Qwen3.5精调模型堆叠在一起:前32层来自Qwopus 3.5-9B-v3.5(将Claude 4.6 Opus的推理风格蒸馏到Qwen作为基础模型),后32层来自Qwen 3.5-9B-GLM5.1-Distill-v1(在相同Qwen基础上使用z.AI的GLM-5.1教师模型的推理数据进行训练)。
假设是:让模型在前半部分推理中采用Opus风格的结构化规划,在后半部分采用GLM的问题分解框架——总共64层,集成在一个模型中。
这种技术被称为直通式弗兰肯斯坦合并——没有混合,没有权重平均,只有原始层堆叠。赫斯林不得不从头编写自己的合并脚本,因为现有工具不支持Qwen 3.5的混合线性/完全注意力架构。
最终的模型通过了44项能力测试中的40项,击败了阿里巴巴的Qwen 3.6-35B-A3B MoE(需要22GB显存),而它仅以Q4_K_M量化在9.2GB显存上运行。理论上,NVIDIA RTX 3060就能轻松处理。
赫斯林解释说,制作这个模型并不容易。原始合并曾产生乱码。但即便如此,他发布的测试模型在爱好者中引起了不小的轰动。
赫斯林的最终修复方案是”治愈精调”——基本上是针对所有注意力和投影的QLoRA(像附录一样嵌入模型并严重影响最终输出的代码片段)。
我们测试发现,虽然让Qwen、Claude Opus和GLM 5.1在本地运行的想法的确诱人,但现实是模型在推理方面过于出色,以至于最终会过度思考。
在M1 MacBook上运行MLX量化版本测试时,当提示生成我们通常的测试游戏时,推理链运行时间过长,达到了令牌限制,在零样本交互中给出了冗长的推理过程,但没有可用的结果。这对于任何想在消费级硬件上本地运行此模型进行严肃应用的人来说都是日常使用的障碍。
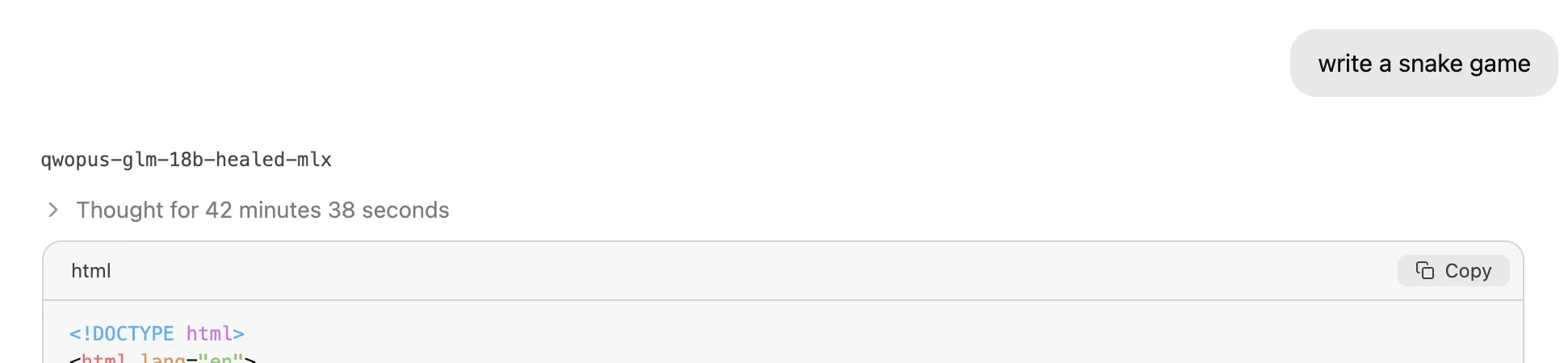
我们稍微降低了要求,情况仍然具有挑战性。一个简单的”编写贪吃蛇游戏”提示在推理上花费了超过40分钟…其中大部分是推理过程。
这是Qwopus系列中已知的紧张关系:Jackrong的v2精调模型旨在解决Qwen 3.5倾向于重复内部循环和”更经济地思考”的问题。在某些提示下,堆叠64层两个推理蒸馏似乎会放大这种行为。
这是一个可解决的问题,开源社区可能会解决它。这里重要的是更广泛的模式:一个化名开发者发布带有完整训练指南的专业精调模型,另一个爱好者用自定义脚本堆叠它们,运行1000个治愈步骤,最终得到一个性能超越全球最大AI实验室之一发布的350亿参数模型的模型。整个东西适合一个小文件。
这就是让开源值得关注的原因——不仅仅是大型实验室发布权重,还有逐层解决方案,在雷达下进行的专业化。随着更多开发者加入社区,周末项目与前沿部署之间的差距正在缩小。
Jackrong随后镜像了赫斯林的存储库,该模型在可用后的前两周内累计下载量超过三千次。
本网站所有区块链相关数据与资料仅供用户学习及研究之用,不构成任何投资建议。转载请注明出处:https://www.lianxinshe666.com/2026/04/22/%e5%bc%97%e5%85%b0%e8%82%af%e6%96%af%e5%9d%a6%e5%bc%8fai%e8%9e%8d%e5%90%88claude-opus%e3%80%81glm%e5%92%8cqwen%ef%bc%8c%e6%80%a7%e8%83%bd%e8%b6%85%e8%b6%8a%e9%a1%b6%e7%ba%a7%e6%a8%a1%e5%9e%8b/





